简介
此教程分为三部分: 1)首先,我们展示了一个异步的事件循环async event loop,并用这个事件循环加上回调函数简单实现了一个网络爬虫,它效率很高,却难于扩展; 2)于是,我们用Python的生成器函数来实现了一些简单的协程coroutines,发现Python的协程是可以做到既高效又可扩展的; 3)最后,我们使用Python3的asyncio标准库的全功能的协程coroutines来重写整个爬虫,并用一个异步队列async queue来协调这些协程。
目标: 并发地爬取多个页面,解析后发现新页面的url,添加到待爬的队列去,直到不再有新的url。
import socket
def fetch(url):
sock = socket.socket()
sock.connect(('xkcd.com', 80))
request = 'GET {} HTTP/1.0\r\nHost: xkcd.com\r\n\r\n'.format(url)
sock.send(request.encode('ascii'))
response = b''
chunk = sock.recv(4096)
while chunk:
response += chunk
chunk = sock.recv(4096)
# Page is now downloaded.
links = parse_links(response)
q.add(links)
Web应用的I/O多线程并发是有所限制的:因为socket的相关操作是阻塞的,每个连接就用一个线程来处理,而线程的代价很高昂,如果面对几十万个并发请求,很快就会消耗光内存,所以线程的代价限制往往成为系统的瓶颈。
Async
现在我们来试试用非阻塞的socket来发请求:
sock = socket.socket()
sock.setblocking(False)
try:
sock.connect(('xkcd.com', 80))
except BlockingIOError:
pass
request = 'GET {} HTTP/1.0\r\nHost: xkcd.com\r\n\r\n'.format('/')
encoded = request.encode('ascii')
while True:
try:
sock.send(encoded)
break # Done.
except OSError as e:
pass
print('sent')
sent
上面的方法面对多个sockets请求时效率不高而且费电,改用Python 3.4中的 DefaultSelector,是一种对使用非阻塞socket时等待事件发生的一种高效方法。
from selectors import DefaultSelector, EVENT_WRITE, EVENT_READ
selector = DefaultSelector()
sock = socket.socket()
sock.setblocking(False)
try:
sock.connect(('xkcd.com', 80))
except BlockingIOError:
pass
def connected():
selector.unregister(sock.fileno())
print('connected!')
selector.register(sock.fileno(), EVENT_WRITE, connected)
SelectorKey(fileobj=60, fd=60, events=2, data=<function connected at 0x107f53f28>)
def loop():
while True:
events = selector.select()
for event_key, event_mask in events:
callback = event_key.data
callback()
loop()
connected!
一个异步网络I/O框架就是基于非阻塞socket和event loop这两个特性,来在单线程中执行并发操作的。
异步(async)并不一定比多线程快,相反,事实常常并非如此,在处理小规模活跃的连接时异步往往比多线程要慢。异步I/O真正适合的场景是,那些含有大量缓慢休眠的、事件稀少的连接的应用。
urls_todo = set(['/'])
seen_urls = set(['/'])
class Fetcher:
def __init__(self, url):
self.response = b'' # Empty array of bytes.
self.url = url
self.sock = None
# Method on Fetcher class.
def fetch(self):
self.sock = socket.socket()
self.sock.setblocking(False)
try:
self.sock.connect(('xkcd.com', 80))
except BlockingIOError:
pass
# Register next callback.
selector.register(self.sock.fileno(),
EVENT_WRITE,
self.connected)
# Method on Fetcher class.
def connected(self, key, mask):
print('connected!')
selector.unregister(key.fd)
request = 'GET {} HTTP/1.0\r\nHost: xkcd.com\r\n\r\n'.format(self.url)
self.sock.send(request.encode('ascii'))
# Register the next callback.
selector.register(key.fd,
EVENT_READ,
self.read_response)
# Method on Fetcher class.
def read_response(self, key, mask):
global stopped
chunk = self.sock.recv(4096) # 4k chunk size.
if chunk:
self.response += chunk
else:
selector.unregister(key.fd) # Done reading.
links = self.parse_links()
# Python set-logic:
for link in links.difference(seen_urls):
urls_todo.add(link)
Fetcher(link).fetch() # <- New Fetcher.
seen_urls.update(links)
urls_todo.remove(self.url)
if not urls_todo:
stopped = True
# Method on Fetcher class.
def parse_links(self):
"""parse response to find all links"""
pass
通过上面这种Callbacks回调的方式来编写的代码,很容易知道出异步(async)编程的问题:spaghetti code(面条式代码),复杂、混乱而难以理解。没有多线程的话,我们是不能够把一系列的计算操作和I/O操作整合到一个方法里,再调度它们来并发运行的。
# Thread-1, 启动一个event loop
stopped = False
def loop():
while not stopped:
events = selector.select()
for event_key, event_mask in events:
callback = event_key.data
callback(event_key, event_mask)
# Thread-2, 启动任意多个非阻塞socket来发送网络请求
# Begin fetching http://xkcd.com/123/
fetcher1 = Fetcher('/123/')
fetcher1.fetch()
# Begin fetching http://xkcd.com/456/
fetcher2 = Fetcher('/456/')
fetcher2.fetch()
# Begin fetching http://xkcd.com/789/
fetcher3 = Fetcher('/789/')
fetcher3.fetch()
# ...
解决办法:Coroutines
class Fetcher:
...
@asyncio.coroutine
def fetch(self, url):
response = yield from self.session.get(url)
body = yield from response.read()
Coroutines协程,是一种可以被中止和唤起的子程序。它结合了回调的效率和多线程编程的美观,来编写async的代码。就像上面这种使用asyncio标准库和aiohttp包,在一个协程里发送一个请求的方式,就很直观。一个线程占50k的内存的话,一个协程只占3k的内存,就很容易扩展。
Coroutines协程的实现有很多种,即使在Python中也有好几种。Python3.4的协程是基于Generators、a Future class和”yield from”声明的,但是到Python3.5时协程就是python语言的一个原生特性了。
Generators的工作原理
import inspect
frame = None
def foo():
bar()
def bar():
global frame
frame = inspect.currentframe()
foo()
print("{}".format(frame.f_code.co_name))
caller_frame = frame.f_back
print("{}".format(caller_frame.f_code.co_name))
bar
foo
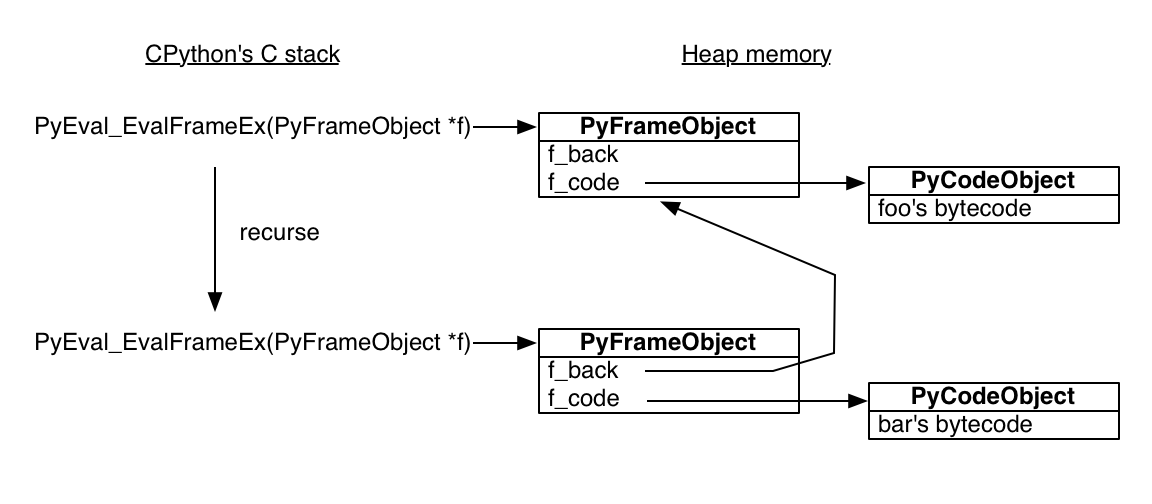
Python的解释器是用C语言写的,其中执行Python函数的方法名叫做PyEval_EvalFrameEx, 这个方法的传入参数是一个Python栈帧对象stack frame,然后在这个栈帧对象的环境下解释Python函数的字节码。注意的是,Python栈帧对象是在堆内存里分配的,而Python的解释器程序的对象是在一般的栈内存里分配的,这就意味着Python的栈帧对象可以outlive它的函数调用。
def gen_fn():
result = yield 1
print('result of yield: {}'.format(result))
result2 = yield 2
print('result of 2nd yield: {}'.format(result2))
return 'done'
gen = gen_fn()
print("生成器的字节码对象名:{}".format(gen.gi_code.co_name))
print("生成器的字节码对象长度:{} bytes".format(len(gen.gi_code.co_code)))
print("生成器的stack frame对象上次执行指令指针:{}".format(gen.gi_frame.f_lasti))
print("生成器第一次调用send返回值:{}".format(gen.send(None)))
print("生成器的stack frame对象上次执行指令指针:{}".format(gen.gi_frame.f_lasti))
print("生成器第二次调用send返回值:{}".format(gen.send('hello')))
print("当前生成器的变量:{}".format(gen.gi_frame.f_locals))
print("生成器第三次调用send返回值:{}".format(gen.send('goodbye')))
生成器的字节码对象名:gen_fn
生成器的字节码对象长度:56 bytes
生成器的stack frame对象上次执行指令指针:-1
生成器第一次调用send返回值:1
生成器的stack frame对象上次执行指令指针:3
result of yield: hello
生成器第二次调用send返回值:2
当前生成器的变量:{'result': 'hello'}
result of 2nd yield: goodbye
---------------------------------------------------------------------------
StopIteration Traceback (most recent call last)
<ipython-input-26-65ed38c94d47> in <module>()
14 print("生成器第二次调用send返回值:{}".format(gen.send('hello')))
15 print("当前生成器的变量:{}".format(gen.gi_frame.f_locals))
---> 16 print("生成器第三次调用send返回值:{}".format(gen.send('goodbye')))
StopIteration: done
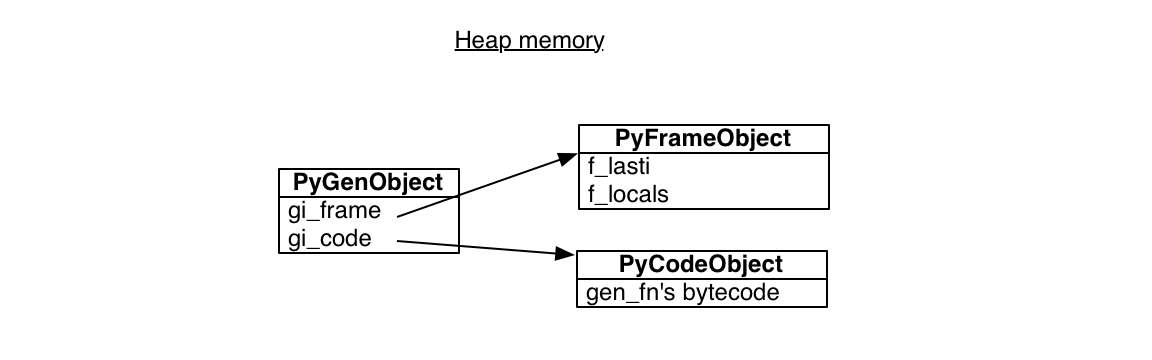
Python的生成器也是基于相同的组件——字节码对象code object和栈帧对象stack frame来实现的。
为什么生成器可以随时随地被唤起呢?正是因为生成器的栈帧对象是分配在堆内存heap memory里的,而不是分配在stack memory里的,不必遵循FILO的栈调用规则。
用Generators来构造Coroutines
生成器既能中断,又能用一个值来继续,还有返回值,看起来很适合用来构建一个简洁的异步编程模型。下面我们来使用generators, futures 和 “yield from”声明来构造一个Python的asyncio标准库里协程的简化版本。
class Future:
"""
用以表示协程等待的未来的某个结果
"""
def __iter__(self):
# Tell Task to resume me here.
yield self
return self.result
def __init__(self):
self.result = None
self._callbacks = []
def add_done_callback(self, fn):
self._callbacks.append(fn)
def set_result(self, result):
self.result = result
for fn in self._callbacks:
fn(self)
# 用futures和coroutines重写我们之前的Fetcher类的fetch方法
class Fetcher:
def __init__(self, url):
self.response = b'' # Empty array of bytes.
self.url = url
self.sock = None
def fetch(self):
self.sock = socket.socket()
self.sock.setblocking(False)
try:
self.sock.connect(('xkcd.com', 80))
except BlockingIOError:
pass
f = Future()
def on_connected():
f.set_result(None)
selector.register(self.sock.fileno(),
EVENT_WRITE,
on_connected)
yield f
selector.unregister(self.sock.fileno())
print('connected!')
Fetcher类的fetch方法现在是一个生成器函数,在yield声明处可以被终止,但是怎么继续呢?我们还需要一个协程驱动器driver,如下:
class Task:
def __init__(self, coro):
self.coro = coro
f = Future()
f.set_result(None)
self.step(f)
def step(self, future):
try:
next_future = self.coro.send(future.result)
except StopIteration:
return
next_future.add_done_callback(self.step)
# 开始爬取网址 http://xkcd.com/353/ 的任务
fetcher = Fetcher('/353/')
Task(fetcher.fetch())
# 开始event loop事件循环
loop()
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-18-64c21f0f034c> in <module>()
15
16 # 开始爬取网址 http://xkcd.com/353/ 的任务
---> 17 fetcher = Fetcher('/353/')
18 Task(fetcher.fetch())
19
TypeError: object() takes no parameters
用yield from声明来factor协程
上面的Fetcher类的fetch方法把之前的connected方法也包含进去了,整个的发送HTTP GET请求、读取响应的过程也都可以放到fetch方法里,而不必再分散到各个回调函数中,如下:
class Fetcher:
def fetch(self):
# ... connection logic from above, then:
sock.send(request.encode('ascii'))
while True:
f = Future()
def on_readable():
f.set_result(sock.recv(4096))
selector.register(sock.fileno(),
EVENT_READ,
on_readable)
chunk = yield f
selector.unregister(sock.fileno())
if chunk:
self.response += chunk
else:
# Done reading.
break
上面的代码看上去就够用了,但我们如何把fetch方法的一坨代码重构成一些子程序呢?Python3的yield from声明这时候就有用了,它能让一个生成器来代理另一个生成器。
# Generator function:
def gen_fn():
# raise Exception('my error') # 测试看看使用yield from的协程是如何做到避免‘stack ripping’的
result = yield 1
print('result of yield: {}'.format(result))
result2 = yield 2
print('result of 2nd yield: {}'.format(result2))
return 'done'
# Generator function:
def caller_fn():
gen = gen_fn()
rv = yield from gen
print('return value of yield-from: {}'.format(rv))
caller = caller_fn()
caller.send(None)
caller.send('hello')
caller.send('goodbye')
result of yield: hello
result of 2nd yield: goodbye
return value of yield-from: done
---------------------------------------------------------------------------
StopIteration Traceback (most recent call last)
<ipython-input-1-2931fdd7d473> in <module>()
17 caller.send(None)
18 caller.send('hello')
---> 19 caller.send('goodbye')
StopIteration:
yield from声明就像一个光滑无摩擦的管道一样,通过它数据可以流进流出子协程。使用yield from来写的协程代理有诸多好处,不仅可以避免‘stack ripping’,而且可以对调用子协程进行异常捕捉处理。
下面对fetch方法里发送HTTP GET请求、读取响应的部分用子协程的方式进行重写:
class Fetcher:
def fetch(self):
# ... connection logic from above, then:
sock.send(request.encode('ascii'))
self.response = yield from read_all(sock)
def read(sock):
f = Future()
def on_readable():
f.set_result(sock.recv(4096))
selector.register(sock.fileno(), EVENT_READ, on_readable)
chunk = yield f # Read one chunk.
selector.unregister(sock.fileno())
return chunk
def read_all(sock):
response = []
# Read whole response.
chunk = yield from read(sock)
while chunk:
response.append(chunk)
chunk = yield from read(sock)
return b''.join(response)
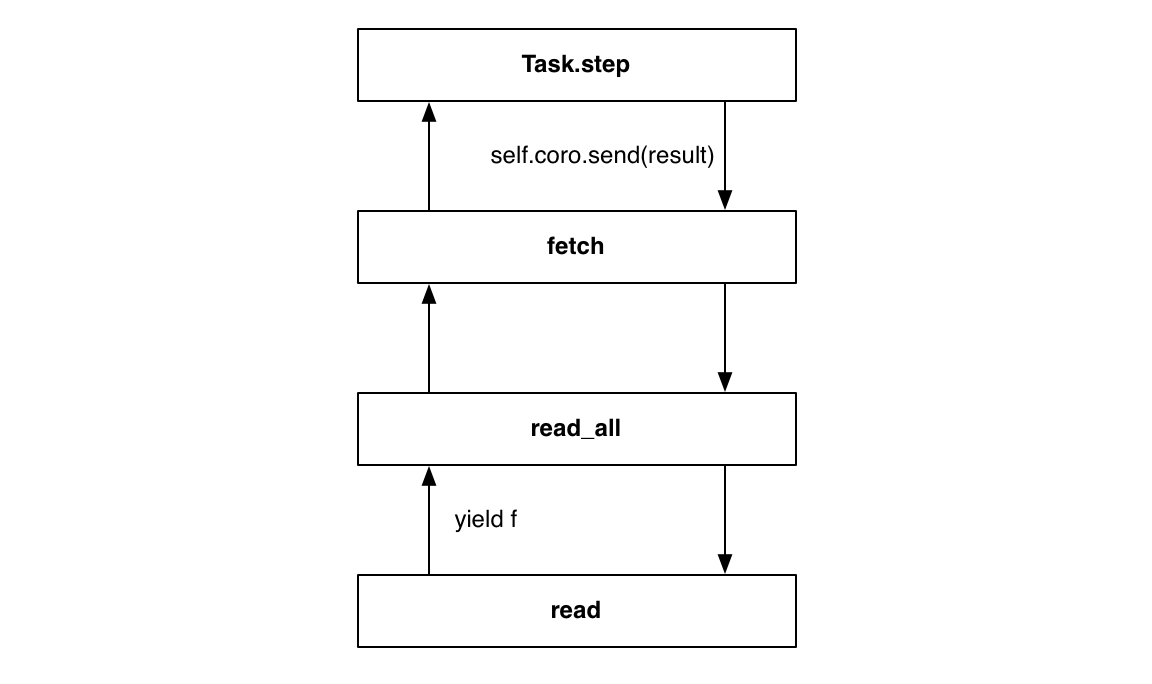
上面的代码中有的地方用yield,有的地方用yield from,为了使代码更精炼优雅,我们想把所有用yield的地方全部改成用yield from,这样的话我们就需要给Future加上下面的方法:
# Method on Future class.
def __iter__(self):
# Tell Task to resume me here.
yield self
return self.result
这里用到了Python代码里生成器和迭代器的内在相似性,于是我们在所有yield f的地方都可以改成yield from f
至此,我们就展示完了Python的asyncio标准库里协程coroutine的原理。我们仔细看过了生成器generators的构造,还完成了futures和tasks的简要实现。可以说asyncio库达到了两个世界的完美实现:并发I/O比线程更高效、比回调更清晰。当然真实的asyncio库的实现要复杂的多,它更注重zero-copy I/O, fair scheduling, exception handling和大量的其它特性。
调度使用协程
现在我们就来使用Python3的asyncio标准库里的协程来重新实现我们之前定义的爬虫。
我们的爬虫会先爬取第一个页面,解析出所有的链接,把新的链接加入到一个待爬url队列去。然后就展开来,并发地爬取新的页面。为了限制客户端和服务端的负载,我们会设置一个能同时运行的workers的最大数目。
想象一下如果是多线程,我们会怎么表达这个爬虫的算法?我们会使用python标准库里的同步队列(synchronized queue),每次有新的项目添加到这个队列中时,队列的任务”tasks”数就+1,每一个worker线程完成它的工作任务后就调用这个队列的task_done方法,而主线程会阻塞在队列的Queue.join方法处,直到每一个被添加到队列的项目都匹配到一个task_done方法调用,然后主线程结束。
协程使用的也是相同的模式,通过利用asyncio库的队列Queue。
try:
from asyncio import JoinableQueue as Queue
except ImportError:
# In Python 3.5, asyncio.JoinableQueue is
# merged into Queue.
from asyncio import Queue
我们在爬虫类中收集所有workers的共享状态,并将主要逻辑写在它的crawl()方法里(相当于一个主线程)。crawl()方法返回的也是一个协程,我们会一直运行asyncio的事件循环,直到crawl()方法结束。
爬虫用一个根URL和最大重定向次数(max_redirect)来初始化,并把这个组合放到它自身的队列Queue里去。所以最开始队列中未完成的任务数就是1。
import asyncio
loop = asyncio.get_event_loop()
crawler = crawling.Crawler('http://xkcd.com', max_redirect=10)
loop.run_until_complete(crawler.crawl())
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-19-61ab2b29a35f> in <module>()
3 loop = asyncio.get_event_loop()
4
----> 5 crawler = crawling.Crawler('http://xkcd.com', max_redirect=10)
6
7 loop.run_until_complete(crawler.crawl())
NameError: name 'crawling' is not defined
crawl协程会开始所有的工作任务,它在join方法处阻塞,直到所有的任务都完成。所有的工作任务都是在后台跑的。
import aiohttp
class Crawler:
def __init__(self, root_url, max_redirect):
self.max_tasks = 10
self.max_redirect = max_redirect
self.q = Queue()
self.seen_urls = set()
# 使用aiohttp的ClientSession来为我们处理连接池和HTTP keep-alives等事务。
self.session = aiohttp.ClientSession(loop=loop)
# Put (URL, max_redirect) in the queue.
self.q.put((root_url, self.max_redirect))
@asyncio.coroutine
def crawl(self):
"""Run the crawler until all work is done."""
workers = [asyncio.Task(self.work())
for _ in range(self.max_tasks)]
# When all work is done, exit.
yield from self.q.join()
for w in workers:
w.cancel() # 在Task的step方法里捕捉CancelledError是如何做到的??
@asyncio.coroutine
def work(self):
while True:
url, max_redirect = yield from self.q.get()
# Download page and add new links to self.q.
yield from self.fetch(url, max_redirect)
self.q.task_done()
@asyncio.coroutine
def fetch(self, url, max_redirect):
# Handle redirects ourselves.
response = yield from self.session.get(url, allow_redirects=False)
try:
if is_redirect(response):
if max_redirect > 0:
next_url = response.headers['location']
if next_url in self.seen_urls:
# We have been down this path before.
return
# Remember we have seen this URL.
self.seen_urls.add(next_url)
# Follow the redirect. One less redirect remains.
self.q.put_nowait((next_url, max_redirect - 1))
else:
links = yield from self.parse_links(response)
# Python set-logic:
for link in links.difference(self.seen_urls):
self.q.put_nowait((link, self.max_redirect))
self.seen_urls.update(links)
finally:
# Return connection to pool.
yield from response.release()
File "<ipython-input-20-d7e3bdb91599>", line 54
else:
^
IndentationError: unindent does not match any outer indentation level
我们在初始化爬虫的时候带了一个剩余重定向次数的参数,每个新的URL都有10次剩余重定向次数,每一次重定向,剩余重定向次数都-1,并把重定向之后的地址放到队列中。
# URL to fetch, and the number of redirects left.
('http://xkcd.com/foo', 10)
('http://xkcd.com/foo', 10)
# URL with a trailing slash. Nine redirects left.
('http://xkcd.com/foo/', 9)
('http://xkcd.com/bar', 10)
('http://xkcd.com/bar', 10)

我们是怎么关闭这个爬虫的:调用每个Task任务的cancel()方法。
生成器的另一个特性:可以从外部向生成器内部抛一个异常。生成器也可以通过throw()唤起,然后向外抛出异常。
# Generator function:
def gen_fn():
result = yield 1
print('result of yield: {}'.format(result))
result2 = yield 2
print('result of 2nd yield: {}'.format(result2))
return 'done'
gen = gen_fn()
gen.send(None) # Start the generator as usual.
gen.throw(Exception('error'))
---------------------------------------------------------------------------
Exception Traceback (most recent call last)
<ipython-input-16-822c9ab2e01d> in <module>()
9 gen = gen_fn()
10 gen.send(None) # Start the generator as usual.
---> 11 gen.throw(Exception('error'))
<ipython-input-16-822c9ab2e01d> in gen_fn()
1 # Generator function:
2 def gen_fn():
----> 3 result = yield 1
4 print('result of yield: {}'.format(result))
5 result2 = yield 2
Exception: error
负责协调任务worker和主协程的队列Queue的实现如下:
from asyncio import Future
import asyncio
class Queue:
def __init__(self):
self._join_future = Future()
self._unfinished_tasks = 0
# ... other initialization ...
def put_nowait(self, item):
self._unfinished_tasks += 1
# ... store the item ...
def task_done(self):
self._unfinished_tasks -= 1
if self._unfinished_tasks == 0:
self._join_future.set_result(None)
@asyncio.coroutine
def join(self):
if self._unfinished_tasks > 0:
yield from self._join_future
程序是如何结束的呢?
class EventLoop:
def run_until_complete(self, coro):
"""Run until the coroutine is done."""
task = Task(coro)
task.add_done_callback(stop_callback)
try:
self.run_forever()
except StopError:
pass
class StopError(BaseException):
"""Raised to stop the event loop."""
def stop_callback(future):
raise StopError
注意,这里的Task类有add_done_callback这样一些方法,看上去更像之前Future的定义?没错,在asyncio的实现里,一个Task就是一个Future。
from asyncio import Future
class Task(Future):
"""A coroutine wrapped in a Future."""
def cancel(self):
self.coro.throw(CancelledError)
def step(self, future):
try:
next_future = self.coro.send(future.result)
except CancelledError:
self.cancelled = True
return
except StopIteration as exc:
# Task resolves itself with coro's return
# value.
self.set_result(exc.value)
return
next_future.add_done_callback(self.step)
正常情况下,一个future通过别人调用它的set_result()方法得到处理,而一个task能够在协程停止后进行自我处理。
总结:
现代的程序越来越多地受限于I/O而非CPU的效率。Python的线程机制常常两边都不讨好:全局的解释器锁让它们并不能够真正地并行执行,而抢先地切换又让线程易于面临竞争。异步Async是正确的处理模式,但基于回调的异步代码变大之后,就会变得一团糟而不好控制。所以协程Coroutines是一个合理的选择,大的协程可以很自然地代理到子协程,也能保证正常的异常处理和堆栈轨迹。
我们上面所看到的,基于生成器的协程(Generator-based coroutines),首先出现在2014年三月推出的Python3.4的asyncio模块中,后来在2015年九月Python3.5出来时就已经被嵌入到Python语言本身中了,用新语法“async def”来取代协程的声明“@asyncio.coroutine”,并且用“await”取代“yield from”来代理到子协程或者等待一个future。
尽管有这些进步,但核心思想不变。Python里新的原生的协程虽然语法上与生成器不同,但工作原理相似,其实它们在Python解释器里共用了同一个实现。Task, Future, 和event loop等类会继续在asyncio中发挥作用。
