
本篇主要介绍Kubernetes架构中包含除etcd和API Server外所有其它的组件。
Scheduler调度器
Controller Manager中运行的Controllers控制器
控制器的工作就是让系统实际的状态逐渐收敛至资源对象所期望的状态。几乎每一种资源都有一种相对应的控制器。资源是对集群中应该运行什么的描述,而控制器就是K8S中活跃的组件,它们在资源对象部署之后执行了实际的操作。
控制器做了很多不同的事情,但它们都利用watch 机制从API Server订阅资源的变化事件,然后执行某些操作。控制器中会运行一个调节循环,把实际的状态调节成期望的状态,并把新的实际状态写进资源的status字段区,但是watch 机制并不能确保控制器不错失任一事件,所以它们也会定时执行re-list操作,确保不会错过任意变化。每一控制器都不知道其它控制器的存在,它们也不会直接交互,都是通过API Server和watch 机制来交互的。
可以查看源码了解每种控制器所做的事情:
kubernetes controllers source code
Kubelet做了些什么
简而言之,Kubelet是负责运行在worker节点上所有事务的组件。它的第一项工作就是通过在API Server上创建一个Node资源来注册一个节点,然后就不间断地监听API Server,判断有哪些Pod被调度到该节点上,启动这些Pod的容器,然后就是不断地监控运行的容器,把它们的状态、事件和资源消耗报告给API Server。Kubelet也是执行容器健康检查存活探针(liveness probes)的组件。
Kubelet也可以脱离API Server,用来从本地的pod manifest文件运行一些静态的pods,比如上篇文章里提到的控制平面组件的Pod。
K8S Service Proxy的角色
kube-proxy保证使用服务IP和port的连接最终能到达支撑服务的某个pod,以及做负载均衡。kube-proxy有两种模式的实现: userspace代理模式和iptables代理模式,后者性能更好,因为它直接使用iptables规则把网络包重定向到一个随机选择的后端pod,只需在内核空间处理,而不用经过用户态空间。
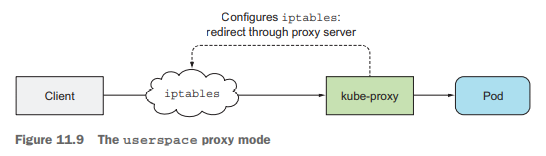
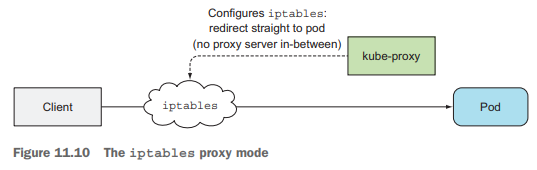
K8S附加组件
- DNS Server
DNS附加组件是以Deployment资源的形式部署的,最新的几个K8S版本用的都是coredns,集群中的所有pods默认都配置成使用集群内部的DNS Server。DNS Server的pod是以kube-dns服务的形式暴露的,它们也使用API Server的watch 机制来监听Service和Endpoints资源的变化,然后更新对应的DNS记录。 - Ingress控制器
Ingress控制器附加组件会运行一个像Nginx一样的反向代理服务器,然后根据集群中的Ingress,Service和Endpoints资源来配置它。所以这个控制器会监听这些资源的变化,更新代理服务器相应的配置。Ingress控制器会把浏览直接传给Service对应的pods,这样可以保留客户端的ip地址信息。
可见DNS Server、Ingress控制器这些附加组件和Controller Manager中运行的控制器很像,只是它们也接收客户端的连接请求外,而不是只和API Server打交道。其它附加组件和这两者也很像,都是监听集群的状态然后执行所需的操作。
控制器是如何协作的
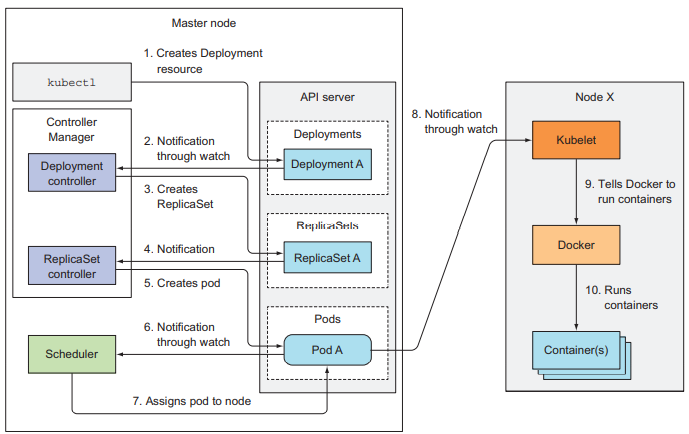
控制平面组件和Kubelet在执行这些操作的时候都会向API Server推送对应的事件(也就是创建Event资源),可以用如下命令查看当前集群中发生的所有事件:kubectl get events --watch
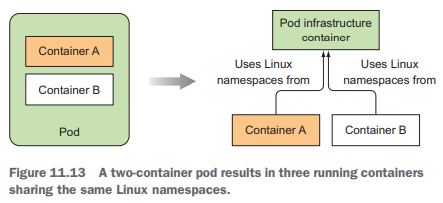
一个运行的pod究竟是什么
对每个运行的pod来说,除了你定义的容器之外,还会多运行一个k8s.gcr.io/pause镜像的容器,这个pause容器不做别的事,它只是用来把一个pod中定义的容器拧和在一起的容器,让它们共享相同的网络和其它Linux namespaces,换句话说,pause容器就是每个pod的基础容器,其唯一的目的就是持有这些Linux namespaces。
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED
0784f262b39d nginx "/docker-entrypoint.…" 3 minutes ago
4f28523b7021 k8s.gcr.io/pause:3.1 "/pause" 3 minutes ago
当普通的业务容器消亡和重启之后,都需要变为和之前相同的Linux namespaces的一部分,pause基础容器让这一点变为可能,因为其生命周期是和pod的生命周期绑定的。
容器是什么
两个术语 Namespace 和 Cgroups。如果有人问你 Linux 上的容器是什么,最简单直接的回答就是 Namesapce 和 Cgroups。Namespace 和 Cgroups 可以让程序在一个资源可控的独立(隔离)环境中运行,这个就是容器了。
Namespace 帮助容器来实现各种计算资源的隔离,Cgroups 主要限制的是容器能够使用的某种资源量。
Pod之间的网络
Pod之间的扁平、无网络地址转换(NAT-less)的网络并不是由Kubernetes建立的,而是由系统管理员或者容器网络接口(CNI)插件建立的。
Pod的IP地址和网络namespace是由pod的基础容器建立并持有的,pod中的所有容器就使用它的网络namespace,在基础容器启动前要先创建一个虚拟以太网接口对(a veth pair),其中一个留在主机Host的网络namespace中,另一个移动到基础容器的网络namespace中并重命名为eth0,这两个虚拟以太网接口就像一个管道的两端,可以进出网络包。在主机网络namespace中的接口再连接到容器运行时配置使用的网络桥(bridge),从中可以给容器分配一个IP地址。不同节点上pod间通信就要求每个节点的网络桥使用不重叠的地址段。
容器网络接口(CNI)项目就是为了让容器连接到网络变得更简单而出现的,Kubernetes可以配置使用任何已有的CNI插件,例如:Calico、Flannel等。
服务是如何实现的
和服务相关的所有事务都是由运行在每个节点上的kube-proxy进程来处理的,服务的IP地址是虚拟的,它没有赋给任何网络接口,也不会出现在网络包的源或目标IP地址中,所以服务的IP地址本身不代表任何东西,你不能ping它们。
每个worker节点上的kube-proxy进程代理既会监听API Server上Service对象的变化情况,也会监听Endpoints对象的变化情况(因为Endpoints对象持有支撑服务的所有pod的ip端口对),并依此创建一些iptables规则,来确保每个目标地址是服务的ip端口的网络包,在内核态目标地址就都会被修改为支撑服务的任一pod的ip端口。
运行高可用的Kubernetes集群
应用上Kubernetes的一大原因就是在基础设施出故障时,不需要或只需要少量的人为干预也能保证应用持续不断地运行。这不仅是要求应用处于存活状态,对控制平面组件要求也是如此。
应用高可用
对不可横向扩展的应用使用Leader选举机制,保证一个leader副本处于活跃状态,多个从副本处于非活跃备用状态,leader故障后选举一个从副本变成leader。Leader选举也可以用于所有副本都处于活跃状态,但只有leader副本提供写操作,其余从副本提供只读操作,避免数据不一致。这种机制并不需要引入到应用本身,可以用sidecar容器的方式通知应用容器何时应变成活跃状态,可以参考示例Kubernetes Leader选举
Kubernetes控制平面组件的高可用
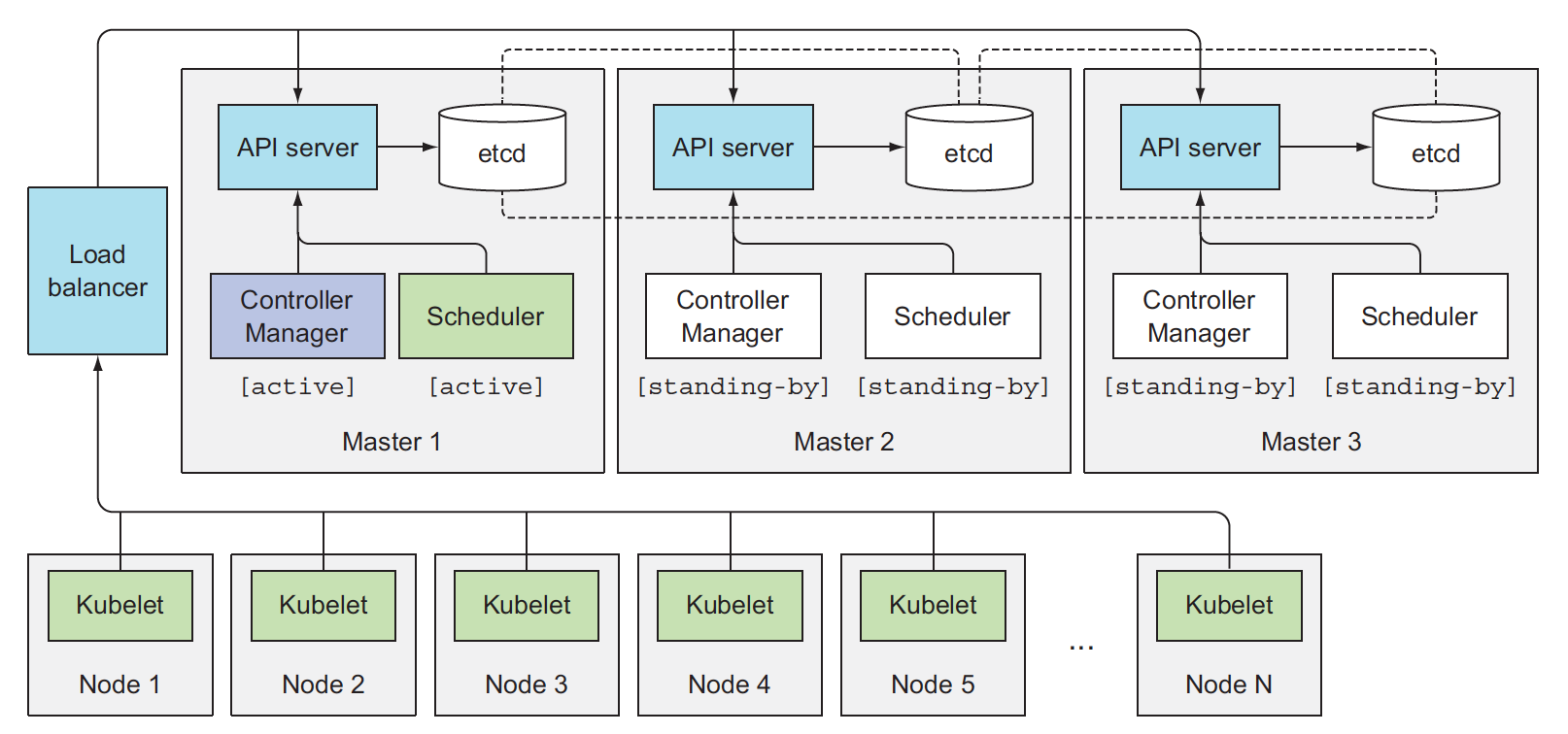 常见的三master节点的高可用Kubernetes集群
常见的三master节点的高可用Kubernetes集群
Controller Manager 或 the Scheduler 组件必须通过Leader选举机制确保同时只有一个副本活跃,其选举机制的实现方式就是通过在API Server中创建一个Endpoints对象资源,因为API Server中资源对象的乐观并发控制机制,只会有一个副本创建成功,然后它就成为Leader副本,其余副本就处于备用状态,leader副本还必须阶段性每2s更新一次这个Endpoints对象资源,让其它副本知道leader副本还存活着。