
Kubernetes的架构原理包含的内容较多,本篇先介绍总体架构,以及etcd和API Server方面的内容。
K8S架构
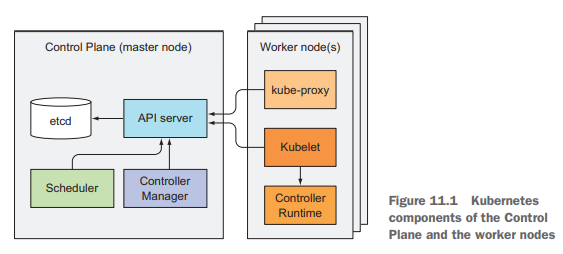
首先,一个K8S集群分为两个部分:
- k8s控制平面组件(master nodes)
- etcd分布式持久化存储
- API Server
- Scheduler
- Controller Manager
- 工作节点组件(worker nodes)
- Kubelet
- k8s服务代理(kube-proxy)
- 容器运行时(Docker, rkt, …)
除此之外,还有一些附加组件:
- k8s DNS server(以前用的是kube-dns, 现在默认用CoreDNS)
- Dashboard
- Ingress 控制器
- Heapster
- 容器网络接口插件(CNI)
# 获取master节点上的控制平面组件的健康状态
$ kubectl get componentstatuses
与API Server的连接基本上都是由其它组件发起的,除了像用kubectl获取日志、kubectl attach和kubectl port-forward这种命令是API Server主动连接Kubelet外。
用kubectl attach可以连到一个正在运行的容器,它与kubectl exec类似,但它是attach到容器中运行的主进程,而不是另起一个进程。
控制平面组件的etcd和API Server可同时运行多个实例,但Scheduler和Controller Manager同时只能各运行一个实例,其它实例只能处于standby模式。
各组件是如何运行的
各控制平面组件和kube-proxy既可以直接部署在系统里,也可以以pod形式运行,而Kubelet是唯一需要以常规系统组件运行的组件,因为是Kubelet让其它的核心组件能以pod形式运行于集群中的。
如下命令的执行结果所示:
# -o custom-columns选项可以用来选择展示的列,--sort-by选项可以用来对资源排序
$ kubectl get po -n kube-system -o custom-columns=POD:metadata.name,NODE:spec.nodeName --sort-by spec.nodeName
# 以下是一个三master节点常见的输出
etcd-consul-4 consul-4
kube-controller-manager-consul-4 consul-4
kube-apiserver-consul-4 consul-4
kube-scheduler-consul-4 consul-4
kube-proxy-ds-amd64-g9h5g consul-4
kube-flannel-ds-x768l consul-4
nginx-ingress-controller-c96864996-t9564 consul-4
etcd-consul-5 consul-5
...
etcd-consul-6 consul-6
...
kube-proxy-ds-amd64-c74v6 izbp1axxxxxxxxxxxxxxxxx
kube-flannel-ds-8qz89 izbp1axxxxxxxxxxxxxxxxx
...
K8S是如何用etcd的
etcd是一个高速分布式一致性KV存储,和它交互的只有API Server(这可以引入一些好处,比如一个健壮的乐观锁系统),它是k8s存储集群状态和元数据的唯一地方。
k8s资源都会带有一个版本号 metadata.resourceVersion,客户端更新资源的时候都必须把版本号传回给API Server,如果版本号与当前存储在etcd中的不匹配,API Server就会拒绝这次更新。
API Server其实就是把资源完整的JSON表示存储在etcd里。
集群化的etcd是如何保证一致性的?
etcd使用Raft共识算法来达成共识,保证一致性。Raft共识算法能保证在任意特定时刻,每个节点的状态要么是集群中大多数节点都同意过的当前状态,要么是大多数节点都同意过的之前某个状态。该算法要求集群中半数以上的节点都同意,才能更新到下一个状态。在网络断开发生脑裂的场景下,只有拥有集群中大多数节点(quorum)的一边才能接受状态更新请求。
Raft共识算法将复杂的一致性问题分解成 Leader 选举、日志同步、安全性三个相对独立的子问题,只要集群一半以上节点存活就可提供服务,具备良好的可用性。
etcd的实例数应该是一个奇数,因为相比奇数个的etcd实例,加1的偶数个的etcd实例的集群的故障率会更高。通常情况下对一个大的集群,5或7个节点的etcd集群也就够用了。
etcd v3相比v2版本的改进之处
在内存开销、Watch 事件可靠性、功能局限上,它通过引入 B-tree、boltdb 实现一个 MVCC 数据库,数据模型从层次型目录结构改成扁平的 key-value,提供稳定可靠的事件通知,实现了事务,支持多 key 原子更新,同时基于 boltdb 的持久化存储,显著降低了 etcd 的内存占用、避免了 etcd v2 定期生成快照时的昂贵的资源开销。
在性能上,首先 etcd v3 使用了 gRPC API,使用 protobuf 定义消息,消息编解码性能相比 JSON 超过 2 倍以上,并通过 HTTP/2.0 多路复用机制,减少了大量 watcher 等场景下的连接数。
API Server做了什么事
API Server通过RESTful API提供了一套CRUD的接口来查询和更新集群状态,除了提供这种一致统一的方式把资源对象存进etcd的功能外,它还对存储的对象做合法性验证,以及在并发更新时提供乐观锁的控制。
当API Server收到一条kubectl的请求时,依次经过的步骤如下所示:
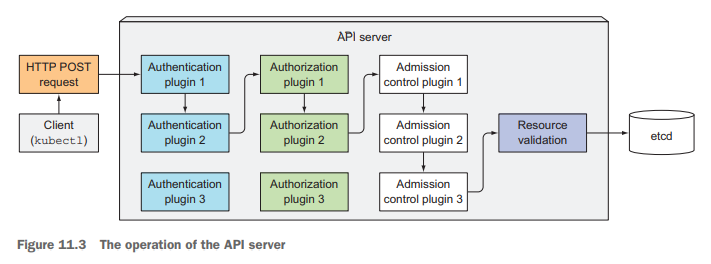
- 调用若干认证(authentication)插件,直到确认客户端的身份;
- 调用若干授权(authorization)插件,直到确认客户端有权限执行操作;
- 如果请求是增删改操作,调用每一个许可控制(Admission Control)插件,会初始化资源定义的一些默认字段,修改相关联的资源等等,例如:AlwaysPullImages、ServiceAccount、NamespaceLifecycle、ResourceQuota等插件;
- 验证资源对象的合法性,然后将其存入etcd;
API Server是如何把资源变化通知到客户端的
watch机制让其它控制平面组件或kubectl能够监听资源的变化情况,当资源被增删改时,它们都能被通知到。
RESTful API的方式是GET /.../pods?watch=true,kubectl的方式是:
$ kubectl get pods --watch
# 甚至打印出整个YAML文件
$ kubectl get pods -o yaml --watch